Tool-Using AI Agents: Web Search, Code Execution & API Integration
Build powerful AI agents with real-world tools. Learn to integrate web search, execute code safely, work with files, and connect to external APIs using LangGraph.
Moshiour Rahman
Advertisement
AI Agents Mastery Series
This is Part 4 of our comprehensive AI Agents series.
| Part | Topic | Level |
|---|---|---|
| 1 | Fundamentals - Build from Scratch | Beginner |
| 2 | LangGraph Deep Dive | Intermediate |
| 3 | Local LLMs with Ollama | Intermediate |
| 4 | Tool-Using Agents | Intermediate |
| 5 | Multi-Agent Systems | Advanced |
| 6 | Production Deployment | Advanced |
Tools Transform Agents
Without tools, agents are just chatbots. With tools, they become autonomous workers:
| Without Tools | With Tools |
|---|---|
| ”I can’t access the internet” | Searches web, retrieves data |
| ”I can’t run code” | Executes Python, returns results |
| ”I don’t know current prices” | Calls APIs, gets real-time data |
| ”I can’t modify files” | Reads, writes, transforms files |
This tutorial covers building production-quality tools for your agents.
Setup
pip install langgraph langchain-openai langchain-community \
tavily-python requests beautifulsoup4 python-dotenv# .env
OPENAI_API_KEY=your-key
TAVILY_API_KEY=your-tavily-key # Free tier availableTool Categories
| Category | Examples | Use Cases |
|---|---|---|
| Information | Web search, Wikipedia, news | Research, fact-checking |
| Computation | Python REPL, calculator, SQL | Data analysis, calculations |
| External APIs | Weather, stocks, databases | Real-time data |
| File Operations | Read, write, convert | Document processing |
| System | Shell commands, processes | Automation |
Building Custom Tools
The @tool Decorator
LangChain’s @tool decorator converts functions into agent-compatible tools:
# custom_tools.py
from langchain_core.tools import tool
from typing import Optional
@tool
def multiply(a: float, b: float) -> float:
"""Multiply two numbers together.
Args:
a: First number
b: Second number
Returns:
Product of a and b
"""
return a * b
@tool
def get_word_count(text: str) -> int:
"""Count the number of words in a text.
Args:
text: The text to count words in
Returns:
Number of words
"""
return len(text.split())The docstring is critical—it tells the LLM when and how to use the tool.
Tool Best Practices
| Do | Don’t |
|---|---|
| Clear, specific docstrings | Vague descriptions |
| Type hints on all params | Missing types |
| Handle errors gracefully | Let exceptions crash |
| Return structured data | Return ambiguous strings |
| Single responsibility | Multi-purpose tools |
Web Search Tools
Tavily Search (Recommended)
Tavily is built for AI agents—returns clean, structured results:
# web_search_tools.py
import os
from langchain_core.tools import tool
from tavily import TavilyClient
from dotenv import load_dotenv
load_dotenv()
tavily = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
@tool
def search_web(query: str, max_results: int = 5) -> str:
"""Search the web for current information.
Args:
query: The search query
max_results: Maximum number of results (default 5)
Returns:
Search results with titles, URLs, and snippets
"""
try:
response = tavily.search(
query=query,
max_results=max_results,
search_depth="advanced"
)
results = []
for r in response.get("results", []):
results.append(f"Title: {r['title']}\nURL: {r['url']}\nSnippet: {r['content'][:200]}\n")
return "\n---\n".join(results) if results else "No results found"
except Exception as e:
return f"Search error: {str(e)}"
@tool
def search_news(query: str) -> str:
"""Search for recent news articles on a topic.
Args:
query: The news topic to search for
Returns:
Recent news articles with headlines and summaries
"""
try:
response = tavily.search(
query=query,
max_results=5,
topic="news"
)
articles = []
for r in response.get("results", []):
articles.append(f"📰 {r['title']}\n{r['content'][:150]}...\nSource: {r['url']}")
return "\n\n".join(articles) if articles else "No news found"
except Exception as e:
return f"News search error: {str(e)}"DuckDuckGo Search (Free, No API Key)
# ddg_search.py
from langchain_core.tools import tool
from langchain_community.tools import DuckDuckGoSearchRun
ddg_search = DuckDuckGoSearchRun()
@tool
def search_duckduckgo(query: str) -> str:
"""Search DuckDuckGo for information. Free, no API key needed.
Args:
query: Search query
Returns:
Search results
"""
try:
return ddg_search.run(query)
except Exception as e:
return f"Search error: {str(e)}"Code Execution Tools
Safe Python REPL
# code_execution_tools.py
import subprocess
import tempfile
import os
from langchain_core.tools import tool
@tool
def execute_python(code: str, timeout: int = 30) -> str:
"""Execute Python code and return the output.
Args:
code: Python code to execute
timeout: Maximum execution time in seconds (default 30)
Returns:
stdout output or error message
"""
# Security: Basic validation
dangerous_patterns = ['os.system', 'subprocess', 'eval(', 'exec(', '__import__', 'open(']
code_lower = code.lower()
for pattern in dangerous_patterns:
if pattern in code_lower:
return f"Security Error: '{pattern}' is not allowed"
try:
# Write code to temp file
with tempfile.NamedTemporaryFile(mode='w', suffix='.py', delete=False) as f:
f.write(code)
temp_file = f.name
# Execute with timeout
result = subprocess.run(
['python', temp_file],
capture_output=True,
text=True,
timeout=timeout,
cwd=tempfile.gettempdir()
)
# Clean up
os.unlink(temp_file)
if result.returncode == 0:
output = result.stdout.strip()
return output if output else "Code executed successfully (no output)"
else:
return f"Error:\n{result.stderr}"
except subprocess.TimeoutExpired:
return f"Timeout: Code execution exceeded {timeout} seconds"
except Exception as e:
return f"Execution error: {str(e)}"
@tool
def execute_shell(command: str) -> str:
"""Execute a shell command (limited to safe commands).
Args:
command: Shell command to execute
Returns:
Command output or error
"""
# Whitelist of safe commands
safe_commands = ['ls', 'pwd', 'date', 'whoami', 'cat', 'head', 'tail', 'wc', 'echo']
cmd_parts = command.split()
if not cmd_parts:
return "No command provided"
base_cmd = cmd_parts[0]
if base_cmd not in safe_commands:
return f"Security Error: '{base_cmd}' is not in the allowed commands list"
try:
result = subprocess.run(
command,
shell=True,
capture_output=True,
text=True,
timeout=10
)
if result.returncode == 0:
return result.stdout.strip() or "Command executed (no output)"
return f"Error: {result.stderr}"
except subprocess.TimeoutExpired:
return "Command timed out"
except Exception as e:
return f"Error: {str(e)}"Data Analysis Tool
# data_analysis_tools.py
from langchain_core.tools import tool
import json
@tool
def analyze_data(data: str, analysis_type: str = "summary") -> str:
"""Analyze data and return statistics.
Args:
data: JSON string of data (list of numbers or objects)
analysis_type: Type of analysis - 'summary', 'describe', or 'aggregate'
Returns:
Analysis results
"""
try:
import statistics
parsed = json.loads(data)
if isinstance(parsed, list) and all(isinstance(x, (int, float)) for x in parsed):
# Numeric list
numbers = parsed
return json.dumps({
"count": len(numbers),
"sum": sum(numbers),
"mean": statistics.mean(numbers),
"median": statistics.median(numbers),
"min": min(numbers),
"max": max(numbers),
"stdev": statistics.stdev(numbers) if len(numbers) > 1 else 0
}, indent=2)
elif isinstance(parsed, list) and all(isinstance(x, dict) for x in parsed):
# List of objects
return json.dumps({
"count": len(parsed),
"keys": list(parsed[0].keys()) if parsed else [],
"sample": parsed[:3]
}, indent=2)
return f"Data type: {type(parsed).__name__}, Length: {len(parsed) if hasattr(parsed, '__len__') else 'N/A'}"
except json.JSONDecodeError:
return "Error: Invalid JSON data"
except Exception as e:
return f"Analysis error: {str(e)}"File Operation Tools
# file_tools.py
from langchain_core.tools import tool
from pathlib import Path
import json
import csv
from io import StringIO
ALLOWED_EXTENSIONS = {'.txt', '.md', '.json', '.csv', '.py', '.js', '.html', '.css'}
MAX_FILE_SIZE = 1_000_000 # 1MB
@tool
def read_file(filepath: str) -> str:
"""Read contents of a file.
Args:
filepath: Path to the file to read
Returns:
File contents or error message
"""
try:
path = Path(filepath)
if not path.exists():
return f"Error: File '{filepath}' not found"
if path.suffix.lower() not in ALLOWED_EXTENSIONS:
return f"Error: File type '{path.suffix}' not allowed"
if path.stat().st_size > MAX_FILE_SIZE:
return f"Error: File too large (max {MAX_FILE_SIZE} bytes)"
content = path.read_text(encoding='utf-8')
if len(content) > 10000:
return content[:10000] + f"\n\n... [Truncated, {len(content)} total characters]"
return content
except Exception as e:
return f"Error reading file: {str(e)}"
@tool
def write_file(filepath: str, content: str) -> str:
"""Write content to a file.
Args:
filepath: Path to write to
content: Content to write
Returns:
Success message or error
"""
try:
path = Path(filepath)
if path.suffix.lower() not in ALLOWED_EXTENSIONS:
return f"Error: File type '{path.suffix}' not allowed"
# Create parent directories if needed
path.parent.mkdir(parents=True, exist_ok=True)
path.write_text(content, encoding='utf-8')
return f"Successfully wrote {len(content)} characters to {filepath}"
except Exception as e:
return f"Error writing file: {str(e)}"
@tool
def parse_csv(filepath: str) -> str:
"""Parse a CSV file and return as JSON.
Args:
filepath: Path to CSV file
Returns:
JSON representation of CSV data
"""
try:
path = Path(filepath)
if not path.exists():
return f"Error: File '{filepath}' not found"
with open(path, 'r', encoding='utf-8') as f:
reader = csv.DictReader(f)
data = list(reader)
# Limit rows for safety
if len(data) > 100:
data = data[:100]
truncated = True
else:
truncated = False
result = {
"rows": len(data),
"columns": list(data[0].keys()) if data else [],
"data": data,
"truncated": truncated
}
return json.dumps(result, indent=2)
except Exception as e:
return f"Error parsing CSV: {str(e)}"
@tool
def list_files(directory: str = ".", pattern: str = "*") -> str:
"""List files in a directory.
Args:
directory: Directory path (default: current directory)
pattern: Glob pattern to match (default: all files)
Returns:
List of files and directories
"""
try:
path = Path(directory)
if not path.exists():
return f"Error: Directory '{directory}' not found"
if not path.is_dir():
return f"Error: '{directory}' is not a directory"
items = list(path.glob(pattern))[:50] # Limit results
result = []
for item in sorted(items):
item_type = "📁" if item.is_dir() else "📄"
size = item.stat().st_size if item.is_file() else "-"
result.append(f"{item_type} {item.name} ({size} bytes)")
return "\n".join(result) if result else "No matching files found"
except Exception as e:
return f"Error listing directory: {str(e)}"API Integration Tools
# api_tools.py
import os
import requests
from langchain_core.tools import tool
from datetime import datetime
import json
@tool
def get_weather(city: str) -> str:
"""Get current weather for a city using OpenWeatherMap.
Args:
city: City name (e.g., "London", "New York")
Returns:
Current weather conditions
"""
api_key = os.getenv("OPENWEATHER_API_KEY")
if not api_key:
# Fallback to simulated data
return f"Weather in {city}: Simulated data - 72°F, Partly Cloudy (set OPENWEATHER_API_KEY for real data)"
try:
url = f"http://api.openweathermap.org/data/2.5/weather"
params = {"q": city, "appid": api_key, "units": "metric"}
response = requests.get(url, params=params, timeout=10)
data = response.json()
if response.status_code == 200:
return json.dumps({
"city": data["name"],
"country": data["sys"]["country"],
"temperature": f"{data['main']['temp']}°C",
"feels_like": f"{data['main']['feels_like']}°C",
"humidity": f"{data['main']['humidity']}%",
"description": data["weather"][0]["description"],
"wind_speed": f"{data['wind']['speed']} m/s"
}, indent=2)
else:
return f"Weather API error: {data.get('message', 'Unknown error')}"
except Exception as e:
return f"Error fetching weather: {str(e)}"
@tool
def get_stock_price(symbol: str) -> str:
"""Get current stock price (simulated).
Args:
symbol: Stock ticker symbol (e.g., AAPL, GOOGL)
Returns:
Stock price information
"""
# Simulated data - replace with real API like Alpha Vantage
import random
simulated_prices = {
"AAPL": 178.50,
"GOOGL": 141.25,
"MSFT": 378.90,
"AMZN": 178.35,
"TSLA": 248.50
}
base_price = simulated_prices.get(symbol.upper(), 100.00)
variation = random.uniform(-5, 5)
current_price = round(base_price + variation, 2)
return json.dumps({
"symbol": symbol.upper(),
"price": current_price,
"currency": "USD",
"change": round(variation, 2),
"change_percent": f"{round(variation/base_price*100, 2)}%",
"timestamp": datetime.now().isoformat(),
"note": "Simulated data - integrate real API for production"
}, indent=2)
@tool
def fetch_url(url: str) -> str:
"""Fetch content from a URL.
Args:
url: The URL to fetch
Returns:
Page content (text only, truncated)
"""
try:
from bs4 import BeautifulSoup
headers = {"User-Agent": "Mozilla/5.0 (compatible; AIAgent/1.0)"}
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Remove scripts and styles
for tag in soup(['script', 'style', 'nav', 'footer', 'header']):
tag.decompose()
text = soup.get_text(separator='\n', strip=True)
# Truncate if too long
if len(text) > 5000:
text = text[:5000] + "\n\n[Content truncated...]"
return text
except Exception as e:
return f"Error fetching URL: {str(e)}"Building the Complete Tool Agent
Now let’s combine everything into a powerful agent:
# tool_agent.py
import os
from dotenv import load_dotenv
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_openai import ChatOpenAI
# Import our tools
from web_search_tools import search_web, search_news
from code_execution_tools import execute_python, execute_shell, analyze_data
from file_tools import read_file, write_file, list_files, parse_csv
from api_tools import get_weather, get_stock_price, fetch_url
load_dotenv()
# Collect all tools
tools = [
# Web Search
search_web,
search_news,
fetch_url,
# Code Execution
execute_python,
execute_shell,
analyze_data,
# File Operations
read_file,
write_file,
list_files,
parse_csv,
# APIs
get_weather,
get_stock_price,
]
# Initialize LLM with tools
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)
# State
class State(TypedDict):
messages: Annotated[list, add_messages]
# Agent node
def agent(state: State) -> State:
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}
# Build graph
builder = StateGraph(State)
builder.add_node("agent", agent)
builder.add_node("tools", ToolNode(tools=tools))
builder.add_edge(START, "agent")
builder.add_conditional_edges("agent", tools_condition)
builder.add_edge("tools", "agent")
tool_agent = builder.compile()
def run_agent(query: str, verbose: bool = True) -> str:
"""Run the tool-using agent."""
if verbose:
print(f"\n{'='*60}")
print(f"🤖 TOOL AGENT")
print(f"Query: {query}")
print('='*60)
result = tool_agent.invoke({
"messages": [{"role": "user", "content": query}]
})
# Extract final response
final = result["messages"][-1]
response = final.content if hasattr(final, 'content') else str(final)
if verbose:
# Show tool usage
for msg in result["messages"]:
if hasattr(msg, 'tool_calls') and msg.tool_calls:
for tc in msg.tool_calls:
print(f"🔧 Tool: {tc['name']}")
print(f"\n📝 Response:\n{response}")
return response
# Example usage
if __name__ == "__main__":
# Web search
run_agent("What are the latest developments in AI agents in 2025?")
# Code execution
run_agent("Calculate the first 10 Fibonacci numbers using Python")
# Multiple tools
run_agent("""
I need to:
1. Get the current weather in Tokyo
2. Search for recent tech news
3. Write a summary to a file called 'daily_brief.txt'
""")
# Data analysis
run_agent("""
Analyze this data and give me statistics:
[23, 45, 67, 89, 12, 34, 56, 78, 90, 11, 33, 55, 77, 99]
""")Tool Execution Flow
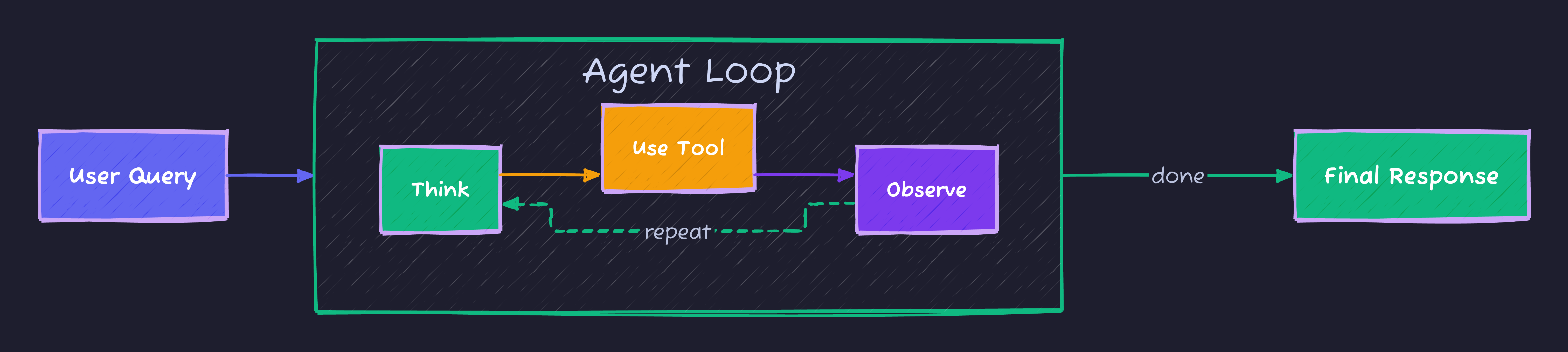
The agent iterates between thinking and tool execution until it has gathered enough information to provide a final response.
Error Handling Patterns
Retry Logic
from langchain_core.tools import tool
import time
@tool
def robust_api_call(endpoint: str, max_retries: int = 3) -> str:
"""Make an API call with automatic retries.
Args:
endpoint: API endpoint URL
max_retries: Maximum retry attempts
Returns:
API response or error details
"""
for attempt in range(max_retries):
try:
response = requests.get(endpoint, timeout=10)
response.raise_for_status()
return response.text
except requests.exceptions.Timeout:
if attempt < max_retries - 1:
time.sleep(2 ** attempt) # Exponential backoff
continue
return "Error: Request timed out after all retries"
except requests.exceptions.HTTPError as e:
return f"HTTP Error: {e.response.status_code}"
except Exception as e:
return f"Error: {str(e)}"Validation Wrapper
def validated_tool(func):
"""Decorator to add input validation to tools."""
@functools.wraps(func)
def wrapper(*args, **kwargs):
try:
return func(*args, **kwargs)
except TypeError as e:
return f"Invalid arguments: {str(e)}"
except Exception as e:
return f"Tool error: {str(e)}"
return wrapperSummary
| Tool Type | Best For | Key Consideration |
|---|---|---|
| Web Search | Current information | Use specialized APIs (Tavily) |
| Code Execution | Calculations, data | Sandbox for security |
| File Operations | Document processing | Validate paths, limit size |
| External APIs | Real-time data | Handle errors, cache results |
What’s Next?
In Part 5, we’ll build multi-agent systems—teams of specialized agents that collaborate to solve complex problems.
Continue to Part 5: Multi-Agent Systems →
Full Code Repository
git clone https://github.com/Moshiour027/ai-agents-mastery.git
cd ai-agents-mastery/04-tools
pip install -r requirements.txt
python tool_agent.pyAdvertisement
Moshiour Rahman
Software Architect & AI Engineer
Enterprise software architect with deep expertise in financial systems, distributed architecture, and AI-powered applications. Building large-scale systems at Fortune 500 companies. Specializing in LLM orchestration, multi-agent systems, and cloud-native solutions. I share battle-tested patterns from real enterprise projects.
Related Articles
AI Agents Fundamentals: Build Your First Agent from Scratch
Master AI agents from the ground up. Learn the agent loop, build a working agent in pure Python, and understand the foundations that power LangGraph and CrewAI.
PythonMulti-Agent Systems: Build AI Teams with CrewAI & LangGraph
Master multi-agent orchestration with CrewAI and LangGraph. Build specialized AI teams that collaborate, delegate tasks, and solve complex problems together.
PythonLangGraph Deep Dive: Build AI Agents as State Machines
Master LangGraph for building production AI agents. Learn state graphs, conditional routing, cycles, and persistence patterns with hands-on examples.
Comments
Comments are powered by GitHub Discussions.
Configure Giscus at giscus.app to enable comments.